







非常用発電機のメンテナンス報告書作成アプリに手書き文字(数字と小数点)認識をつけようと思い、せっかくなのでCoreMLを使ってみました。意外と情報が少なかったので備忘録も兼ねて載せておきます。参考にしたのはCoreMLではじめる機械学習です。あと画像のピクセル色を拾うところはこの記事を参考にしてます。
まずはKerasでmlmodelを作成します。
import keras
import numpy as np
from keras.datasets import mnist
from keras.layers import Dense, Dropout, Activation, Conv2D, MaxPooling2D, Flatten
(trainData, trainAnswer), (testData, testAnswer) = mnist.load_data()
#学習用データとテスト用データ作成
trainData = trainData.reshape(60000,28,28,1) / 255
testData = testData.reshape(10000,28,28,1) / 255
answer = keras.utils.to_categorical(trainAnswer, num_classes=10)
tanswer = keras.utils.to_categorical(testAnswer, num_classes=10)
model = keras.models.Sequential()
model.add(Conv2D(10, (5, 5),
input_shape=(28,28,1), padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(10, (5, 5), padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(10, (5, 5), padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(512, activation='relu', use_bias=True))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
model.fit(
trainData,
answer,
epochs=5,
batch_size=100,
validation_data=(testData, tanswer)
)
#coremltoolsでmlmodelを出力
import coremltools
coreml_model = coremltools.converters.keras.convert(model)
coreml_model.save("Mnist.mlmodel")
わたしは機械学習は初心者なのであまりあてにはならないのですが、このコードでは畳み込みとプーリングを3回繰り返した後Affin-ReLUを一度通して出力層でsoftmax関数にかけています。Dropoutとか本当に意味あるのかは不明。epochsを5に設定することで、同じデータで5回学習しています。もっとたくさん学習させると精度は上がってそうな気がしますすが、時間もかかるし、これでも98%くらい当たってるみたいなので良しとしてます。
最後のところでcoremltoolsを使ってmlmodelを出力しています。もちろん事前にcoremltoolsをインストールしておく必要があります。
ここで作成されたMnist.mlmodelを、XCodeのプロジェクトにドラッグドロップで放り込みます。
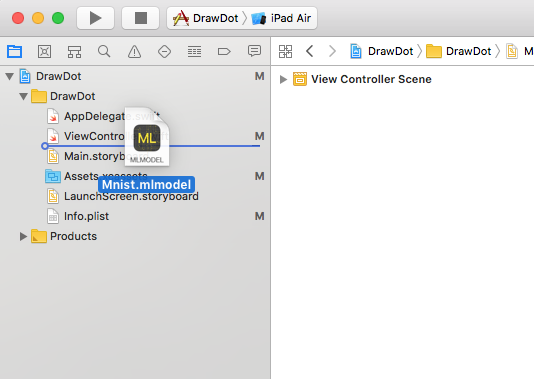
そうすると自動でMnistクラスが作成されます。
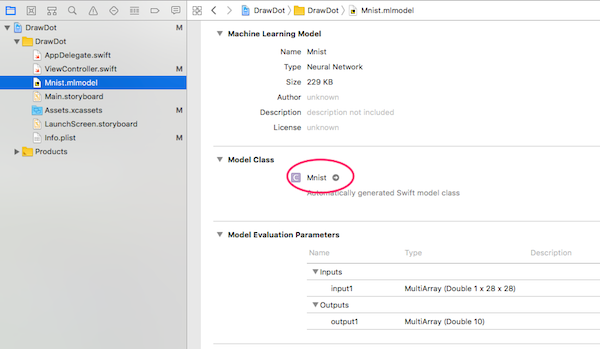
上図の右矢印ボタンを押すとソースコードが表示されます。読んでみるとMLMultiArrayを入力してMLMultiArrayを出力するみたいです。でもMLMultiArrayっていうのが聞いたこともないし、何だかよくわからなくて苦労しました。
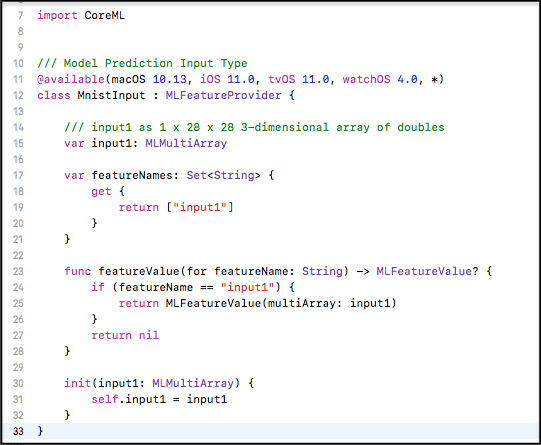
ソースコードのコメントによると「input1 as 1 x 28 x 28 3-dimensional array of doubles」とあるので、Kerasで作ったモデルの入力が(w28*h28*c1)になっているのでそれに対応しているんでしょうが、3次元の配列を突っ込めばよさそうな感じです。
MLMultiArrayのコンストラクタにはinit(shape: [NSNumber], dataType: MLMultiArrayDataType)っていうのがあるので、一見するとshapeに[1,1,28]とか入れれば良さそうな感じなのですが、それで初期化しても1次元の配列みたいな動きしかしないんですね。どうしたもんかと思っていろいろ試していると、785番目の要素にアクセスしたらアプリが落ちたので、ハタと気づきました。配列の値は一次元でのべーっと入れて、そしたら内部で勝手にリシェイプしてくれるんじゃないかって。気づいてみればどうということはないのですが、結構かかりました。できたのが以下のコードです。
override func viewDidLoad() {
super.viewDidLoad()
let model = Mnist()
//画像をリサイズして配列に格納
let image = UIImage.init(named: "num")
let arr = getByteArrayFromImage(imageRef:(image?.cgImage!)!)
//MLMultiArrayを初期化
let mlarr = try! MLMultiArray.init(
shape: [1,28,28],
dataType: MLMultiArrayDataType.double
)
let count = arr.count
var j = 0
for i in (0..<count) {
//実際に画像は複数チャネル持ってるので、最初のチャネルだけ使う
if i % (count / 784) == 0{
mlarr[j] = NSNumber.init(value:Double(255 - Int(arr[i])))
j += 1
}
}
let input = MnistInput.init(input1: mlarr)
let output = try! model.prediction(input: input)
print(output.output1)
}
func getByteArrayFromImage(imageRef: CGImage) -> [UInt8] {
//画像リサイズして配列にする
var img = CIImage.init(cgImage: imageRef)
let scale = 28.0 / CGFloat(imageRef.width)
let trans = CGAffineTransform.init(scaleX: scale, y: scale)
img = img.transformed(by: trans)
let img2 = img.cgImage
let data = img2?.dataProvider!.data
let length = CFDataGetLength(data)
var rawData = [UInt8](repeating: 0, count: length)
CFDataGetBytes(data, CFRange(location: 0, length: length), &rawData)
return rawData
}
UIImageで28*28の文字画像を作って読み込ませると、[0,0,0,0,0,0,0,0,1,0]こんな感じで答えが出てきます。
そんなに大したことしてないのに当てちゃうんだから、機械学習ってホント不思議ですよね。
 法令
法令
 容量計算
容量計算 技術資料
技術資料 申請・届出
申請・届出


